
Очевидно, мы создаем контент с какой-то целью и надеемся, что кто-то будет взаимодействовать с ним определенным образом. Допустим, цели нам обозначили в техническом задании. Осталось ответить на вопрос: «Кто та группа людей, которая будет читать наш контент?» Это важный вопрос, поскольку он будет направлять нас на каждом этапе реализации контента.
Вы можете спросить: «Почему бы не погрузиться в чертоги собственного разума и не выудить ответ?» Во многих компаниях любят писать и разрабатывать для себя. Или думают о себе как о пользователе. Плохая идея. Лучше честно разобраться: кто на самом деле будет это читать, что им нужно сделать, с какими проблемами они сталкиваются. Тогда контент выйдет значительнее эффективнее.
Пример:
- Если у вас есть ребенок в возрасте 7 лет и вы активно пользуетесь сервисом для обучения детей 5-10 лет и в то же время разрабатываете его, то вы являетесь целевой аудиторией (ЦА) продукта, если готовы непредвзято оценить продукт.
- Если вы только разрабатываете продукт, то вы — не ЦА продукта.
- Если пользуетесь продуктом, то вы — ЦА.
Разработчик продукта
≠
его пользователь
Что такое data-driven подход?
Data-driven подход — это методология принятия решений, основанная на анализе фактических данных, а не на интуиции или предположениях. В контент-маркетинге это означает:
- Сбор и анализ метрик взаимодействия пользователей
- Использование количественных данных для выбора тем и форматов
- Тестирование гипотез с измеримыми результатами
- Корректировка стратегии на основе реальной обратной связи
Кейс: определение и анализ целевой аудитории IT-издания
Например, мы составляем контент-план для крупного IT-издания с целью как минимум выйти в ноль, как максимум — получить прибыль 2 млн руб. за месяц. Кто же целевая аудитория и какие у нее потребности?
Первое, на что обращаем внимание — это аббревиатура «IT».
Второе — «издание».
Третье — «крупное».
И, наконец, задаем вопрос стейкхолдеру — каков бюджет?
Разработчики встречаются разные. Если делить их по грейдам, то получим:
- Войтивайтишники
- Стажеры
- Джуны
- Мидлы
- Сеньоры
- Тимлиды
- Архитекторы
Разработчики пишут на разных языках, владеют разными фреймворками:
- Python
- JavaScript / TypeScript
- C/C++
- C#
- Go
- PHP
- Rust
- и т. д.
В итоге получаем внушительное количество комбинаций. Приходит ответ от стейкхолдера: бюджет на все материалы, бильд-редактора и SEO-специалиста — 150 000 руб. Ха. Здесь благоразумно отказаться от проекта. Но в учебных целях давайте продолжать. Начнем сужать ЦА.
Первый шаг: что говорят продажники
Спрашиваем отдел продаж (или другое компетентное лицо) — на чем зарабатывает компания или планирует зарабатывать. Или конкретнее: какие языки котируются у рекламодателей. Получаем ответ — Rust и C++ войтивайтишного, джуновского и мидл-уровня.
Второй шаг: собираем интерактивные (социальные) данные
Здесь начинается data-driven подход. Вместо гаданий о предпочтениях аудитории мы собираем конкретные метрики взаимодействия.
Интерактивные данные описывают взаимодействие пользователей с контентом и отношение к нему.
Примеры:
- Лайки: ❤️ 1247 лайков
- Репосты: 🔄 89 репостов
- Комментарии: 💬 156 комментариев
- Просмотры: 👁️ 12 450 просмотров
- Сохранения: 🔖 67 сохранений в избранное
- Реакции: 😂😮😢😡 различные эмодзи
Вспоминаем, что компания крупная — значит есть данные, которые можно:
- Получить
- Очистить
- Отфильтровать
- Отсортировать
Пишем скраперы для сайта, соцсетей и тг-чатов, собирающие лайки, количество просмотров статей, количество кликов по сокращенным ссылкам и т. п. Полученные данные представляем в виде таблички и сортируем ее в порядке убывания интересующей нас метрики.
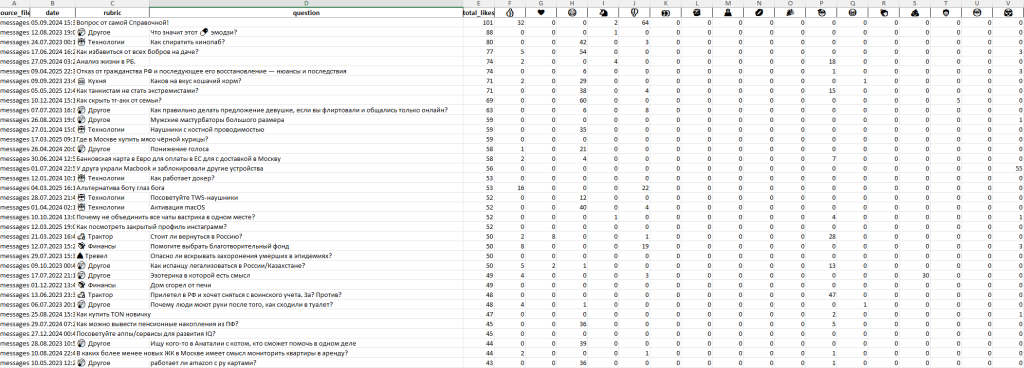
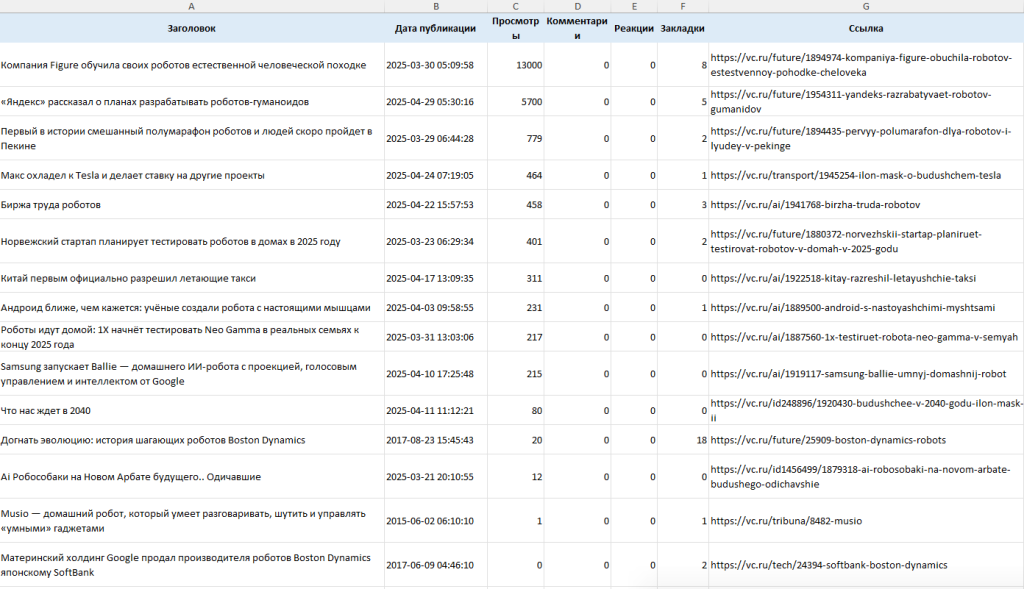
А скормив комментарии нейросети, получим тональность — какие эмоции и отношение выражают пользователи в своих сообщениях, комментариях, отзывах.
Итак, перед нами 200 статей и 200 постов по Rust и C++, которые пользователи прочли от корки до корки, лайкнули, репостнули и сохранили в закладках и т. д. Достаточно ли этого? Не совсем: может быть нашим ресурсом пользуется всего один-два сегмента ЦА, а все остальные пользователи посещают ресурсы конкурентов.
Цифры не врут
если смотреть на них объективно
Третий шаг: анализ конкурентов
Чтобы не вариться в собственном соку и не замыкаться в себе, повторяем второй шаг с конкурентами: Хабр, Скиллбокс Медиа, Журнал «Код», Dev.to, Medium, Substack и т. д.
Четвертый шаг: создаем персоны
Имея на руках данные о собственной аудитории и конкурентах, мы можем составить портрет целевой аудитории и понять, какой контент действительно работает.
Что у нас есть:
- Бизнес-приоритеты от отдела продаж (Rust и C++ для войтивайтишников, джунов и мидлов)
- Метрики по 200+ материалам
- Тональность комментариев и обратной связи
- Анализ успешных практик конкурентов
Объединяем все данные и создаем 2-3 детальные персоны. Например:
Персона 1: Алексей, Rust-разработчик, джун
- Возраст: 23-27 лет
- Опыт: 1-2 года
- Боли: поиск первой работы, прокачка навыков
- Интересы: туториалы, разборы кода, карьерные советы
- Поведение: читает в обед, сохраняет полезные статьи, активно комментирует
Персона 2: Мария, C++ разработчик, мидл
- Возраст: 28-35 лет
- Опыт: 3-5 лет
- Боли: рост до сеньора, выбор технологий, work-life balance
- Интересы: архитектурные решения, производительность, управление командой
- Поведение: читает вечером, делится знаниями в корпоративных чатах

Пятый шаг: тестируем гипотезы
Запускаем A/B тесты на небольших сегментах аудитории:
- Разные форматы контента (лонгриды vs короткие посты)
- Время публикации
- Стиль подачи (технический vs разговорный)
- Типы заголовков
Коротко о главном
- Не полагайтесь на интуицию. Писать «для себя» — прямой путь к провалу. Разработчик продукта ≠ его пользователь. Только реальные данные покажут, кто ваша аудитория и что ей нужно.
- Начинайте с бизнес-целей. Прежде чем изучать аудиторию, выясните у продажников или стейкхолдеров: на чем компания зарабатывает? Это определит приоритеты в создании контента.
- Данные важнее предположений. Собирайте метрики взаимодействия (лайки, репосты, время чтения), анализируйте тональность комментариев, изучайте успешные практики конкурентов. Цифры не врут.
- Создавайте детальные персоны. Недостаточно знать, что аудитория — «айтишники». Нужны конкретные портреты: возраст, опыт, боли, интересы, поведенческие паттерны. Это основа для таргетированного контента.
- Тестируйте гипотезы. A/B-тестирование форматов, времени публикации, стилей подачи и т. д. поможет найти оптимальную стратегию для каждого сегмента аудитории.
Результат: вместо интуитивного «пишем для айтишников» и гадания на кофейной гуще применяем data-driven стратегию — подход, основанный на фактических данных о поведении пользователей, который приносит измеримые результаты.
